เนคเทค สวทช.-วช. ผนึกกำลังติวเข้ม 24 หน่วยงาน ปั้น ‘LLM สัญชาติไทย’ จุดไฟนวัตกรรมสืบค้นอัจฉริยะ ขับเคลื่อน AI ไทยสู่ระดับสากล

(วันที่ 23 มกราคม 2569) อุทยานวิทยาศาสตร์ประเทศไทย จ.ปทุมธานี: สำนักงานพัฒนาวิทยาศาสตร์และเทคโนโลยีแห่งชาติ (สวทช.) โดย ศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติ (เนคเทค) ร่วมกับ สำนักงานการวิจัยแห่งชาติ (วช.) จัดกิจกรรม Bootcamp: พัฒนาระบบสืบค้นด้วย LLM สัญชาติไทย ระหว่างวันที่ 23–25 มกราคม 2569 ณ บ้านวิทยาศาสตร์สิรินธร สวทช. เพื่อยกระดับศักยภาพบุคลากรจาก 24 หน่วยงาน ทั้งภาครัฐและเอกชนให้สามารถพัฒนาและประยุกต์ใช้เทคโนโลยีปัญญาประดิษฐ์ภาษาไทยสำหรับงานสืบค้นเอกสารและองค์ความรู้ขององค์กรได้อย่างเป็นรูปธรรม

นางสาวเสาวนีย์ มุ่งสุจริตการ รองผู้อำนวยการ วช. ประธานในพิธีเปิดกิจกรรม กล่าวว่า วช. จัดทำฐานข้อมูลด้านวิทยาศาสตร์ วิจัยและ นวัตกรรมของประเทศ เพื่อประโยชน์ในการบูรณาการ บริหารจัดการ และวิเคราะห์ สังเคราะห์ข้อมูลการวิจัยและนวัตกรรมในภาพรวมของประเทศ รวมถึงให้เกิดความร่วมมืออย่างมีประสิทธิภาพระหว่างทุกภาคส่วนในระบบวิจัย วช. จึงให้ความสำคัญกับการนำเทคโนโลยี Large Language Model (LLM) ภาษาไทย มาใช้ในการยกระดับระบบสารสนเทศด้านวิทยาศาสตร์ วิจัย และนวัตกรรมของประเทศ เนื่องจากภาษาไทยมีโครงสร้างและบริบทเฉพาะ การมีโมเดลภาษาไทยที่มีประสิทธิภาพจะช่วยให้ระบบ AI สามารถเข้าใจและประมวลผลข้อมูลได้อย่างแม่นยำ ลึกซึ้ง และสามารถนำไปใช้ประโยชน์ได้จริงทั้งในภาครัฐ ภาคธุรกิจ และภาควิชาการ

ด้าน ดร.ศวิต กาสุริยะ รองผู้อำนวยการเนคเทค สวทช. กล่าวว่า เนคเทคในฐานะหน่วยงานวิจัยและพัฒนาฐานรากเทคโนโลยีดิจิทัลของประเทศ มุ่งผลักดันการนำผลงานวิจัยด้าน AI ภาษาไทยสู่การใช้งานจริงในหน่วยงานภาครัฐและองค์กรต่าง ๆ กิจกรรม Bootcamp ครั้งนี้เป็นการขยายผลจาก “โครงการพัฒนาระบบสืบค้นและถาม–ตอบ ข้อมูลสารสนเทศด้านวิทยาศาสตร์ วิจัย และนวัตกรรม โดยใช้โมเดลภาษาไทยขนาดใหญ่” ซึ่งดำเนินการโดย เนคเทค สวทช. เพื่อพัฒนาศักยภาพบุคลากรด้าน AI และ Big Data สร้างเครือข่ายความร่วมมือ และการแลกเปลี่ยนข้อมูลคุณภาพสูงระหว่างหน่วยงานวิจัย นำไปสู่ระบบสืบค้นองค์ความรู้วิจัยที่ค้นง่าย หาเจอ และเพิ่มโอกาสในการใช้ประโยชน์จากงานวิจัยของประเทศ โดยกิจกรรมครั้งนี้มีหน่วยงานผ่านการคัดเลือกเข้าร่วม Bootcamp จำนวน 24 หน่วยงาน จำนวนกว่า 100 คน จากผู้สมัคร 31 หน่วยงานภาครัฐ ภาคเอกชน และสถาบันการศึกษา


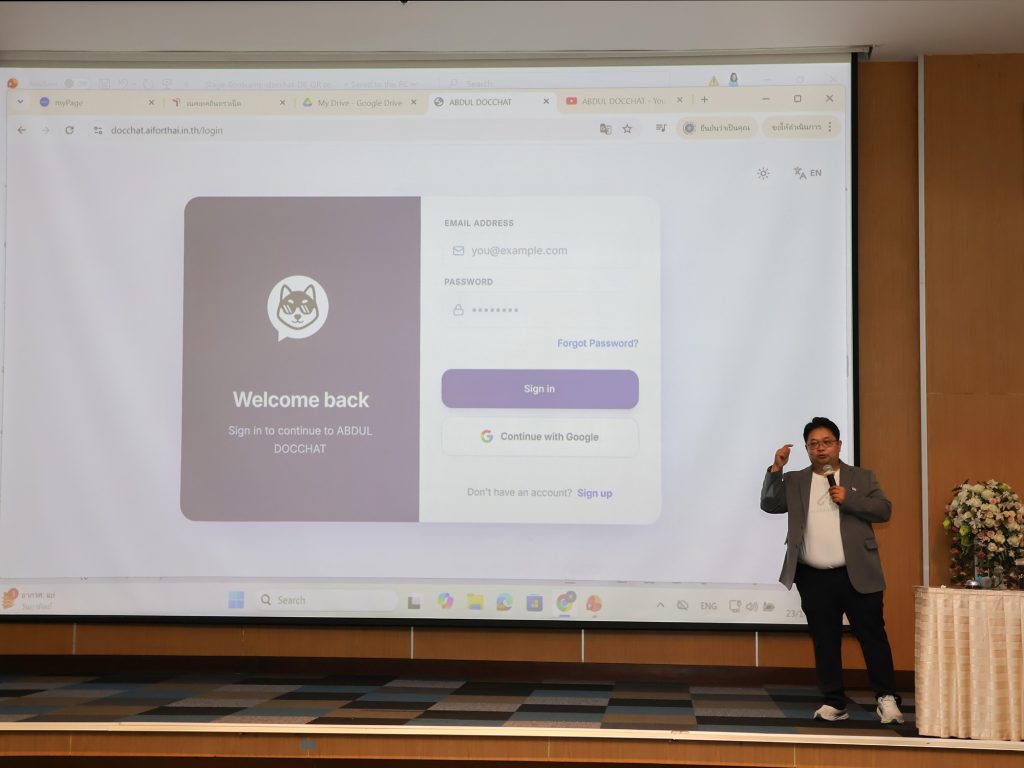

กิจกรรม Bootcamp ดังกล่าวจัดขึ้นภายใต้แนวคิด “จุดไฟนวัตกรรมวิจัยด้วย LLM สัญชาติไทย” มุ่งสร้างความเข้าใจเชิงลึกเกี่ยวกับเทคโนโลยี Large Language Model (LLM) ภาษาไทย เพื่อรองรับการใช้งานจริงในหน่วยงานภาครัฐและภาควิชาการ โดยตลอดระยะเวลา 3 วัน ผู้เข้าร่วมจะได้เรียนรู้ผ่านการบรรยายควบคู่กับการทำเวิร์กช็อปอย่างเข้มข้น ตั้งแต่การเตรียมและประมวลผลข้อมูลเอกสารภาษาไทย การทำ OCR และ Text Cleaning การสร้างระบบ RAG ขั้นพื้นฐานและขั้นสูง การประยุกต์ใช้เทคนิค Hybrid Search, Re-ranking และ Conversation Memory ไปจนถึงการออกแบบ AI Agents สำหรับงานเอกสารและ Workflow อัตโนมัติ โดยใช้แพลตฟอร์ม LLM สัญชาติไทย เป็นแกนหลักของการพัฒนา
นอกจากนี้ ในวันสุดท้ายของกิจกรรมผู้เข้าร่วมจากทั้ง 24 หน่วยงานจะได้นำเสนอ Use Case และต้นแบบระบบสืบค้นที่พัฒนาจากข้อมูลจริงของแต่ละหน่วยงาน พร้อมรับข้อเสนอแนะจากผู้เชี่ยวชาญ เพื่อนำไปต่อยอดสู่การใช้งานจริงในองค์กรของตนเอง กิจกรรม Bootcamp ครั้งนี้ถือเป็นอีกก้าวสำคัญของความร่วมมือระหว่าง วช. เนคเทค สวทช. และ หน่วยงานพันธมิตรในการผลักดัน AI ภาษาไทย เพิ่มประสิทธิภาพการบริหารจัดการองค์ความรู้ และขับเคลื่อนระบบวิจัยของประเทศ